

Your RAID Backup Isn’t Really Backup. Your Customers Will Find Out the Hard Way
A single drive failure at 2 a.m. shouldn’t take a customer’s machine offline, yet that’s exactly what happens when OEMs or embedded device manufacturers treat RAID as a “raid backup strategy.” The confusion between fault tolerance and true data protection shows up fast in the field: extended service calls, missed SLAs, and frustrated end users who just need their system back online.
RAID keeps a machine running when a disk dies. That’s it. It was never designed to protect against ransomware, accidental deletion, corrupted files, failed updates, or an operator who pulls power without a clean shutdown. If your current “backup plan” inside an embedded system is just a RAID array, you’re one incident away from learning the difference the hard way.
RAID Backup: Why the Term Is Dangerously Misleading
RAID stands for Redundant Array of Independent Disks. It mirrors or stripes data across multiple drives to keep a system available if one drive fails. That word “redundant” trips people up, because redundancy sounds a lot like protection.
It’s not. Redundancy and backup solve fundamentally different problems. RAID is an availability technology that prevents downtime from hardware failure. Backup is a recovery technology that lets you restore data after it’s been lost, corrupted, or encrypted by malware. Disk imaging goes one step further as a rapid system restoration technology that captures your entire operating environment for bare-metal recovery.
When someone says “raid backup,” they’re usually describing a setup that handles only one of these three layers. That gap is where real-world disasters happen.
What RAID Actually Protects (and What It Doesn’t)
RAID 1 mirrors data across two drives, so if one fails, the other takes over seamlessly. RAID 5 and RAID 6 use parity data to survive one or two simultaneous drive failures. RAID 10 combines mirroring and striping for both speed and redundancy. All of these keep a system online during a hardware event.
None of them help when ransomware encrypts every file on the array. RAID faithfully mirrors corrupted data to every drive in real time. Delete a critical folder by accident? RAID replicates that deletion instantly too. A failed RAID controller can also take the entire array offline, and in many cases the disks can’t simply be moved to another system and read normally because the array is tied to the original hardware. These aren’t edge cases. They’re common scenarios in OEM deployments where systems run unattended, live in less-controlled environments, and are supported by field technicians - not an on-site IT team.
The OEM Reality: Why RAID Fails Inside Customer-Deployed Machines
OEM systems have a different risk profile than traditional IT. You’re shipping a purpose-built machine - think diagnostic equipment, inspection systems, kiosks, lab analyzers, packaging/labeling controllers, edge gateways, and other specialized platforms - into customer environments you don’t control. These systems often operate for years, with limited maintenance windows and limited on-site technical skill.
RAID can improve uptime during a single-drive failure, but it doesn’t reduce the most common causes of “can’t boot,” “application won’t start,” or “data is gone” incidents that drive support costs in the field.
Real Threats RAID Can’t Address in OEM Deployments
Improper shutdowns and sudden power loss can corrupt file systems or interrupt writes in progress. RAID doesn’t protect against this because it only provides disk redundancy, not recovery from corruption or incomplete writes. If damaged or corrupted data is written to the array, RAID simply mirrors that state across the disks.
Software updates and driver changes can break boot sequences or destabilize critical applications, and RAID will happily mirror that broken state. Malware and ransomware can reach embedded Windows and Linux systems through remote access tools, exposed services, removable media, or customer networks - and RAID replicates the damage across the array in real time.
SC World reports that only 29% of organizations use layered ransomware protection for their backups, while 13% have no ransomware protection on offsite backups at all. If many organizations aren’t even protecting their actual backups, a RAID-only approach inside customer-deployed equipment is even more exposed.
RAID disks also still share the same machine and power source, meaning physical damage, theft, fire, or electrical failure can compromise the entire array at once. That’s why critical systems often require off-box or offsite backups in addition to local recovery images.
Finally, there’s the OEM-specific reality: time-to-recovery is a product feature. If a system needs a multi-hour rebuild, specialized technician time, or a return-to-depot event, your total cost of support skyrockets and customer trust drops. RAID doesn’t solve that.
Converting RAID to a Real Backup Strategy (for OEM Machines)
Here’s the good news: you don’t need to throw out your existing hardware. A practical OEM-friendly approach is to repurpose a two-drive “RAID mindset” into a primary drive plus a dedicated backup drive. Instead of mirroring every write in lockstep, you designate one drive as the active system disk and use the other as a protected backup target.
This is where imaging software becomes the linchpin of your protection strategy. A solution like Macrium LTSC captures a complete system image from the primary drive and stores it on the secondary drive on a scheduled basis. You get point-in-time recovery that RAID simply cannot offer.
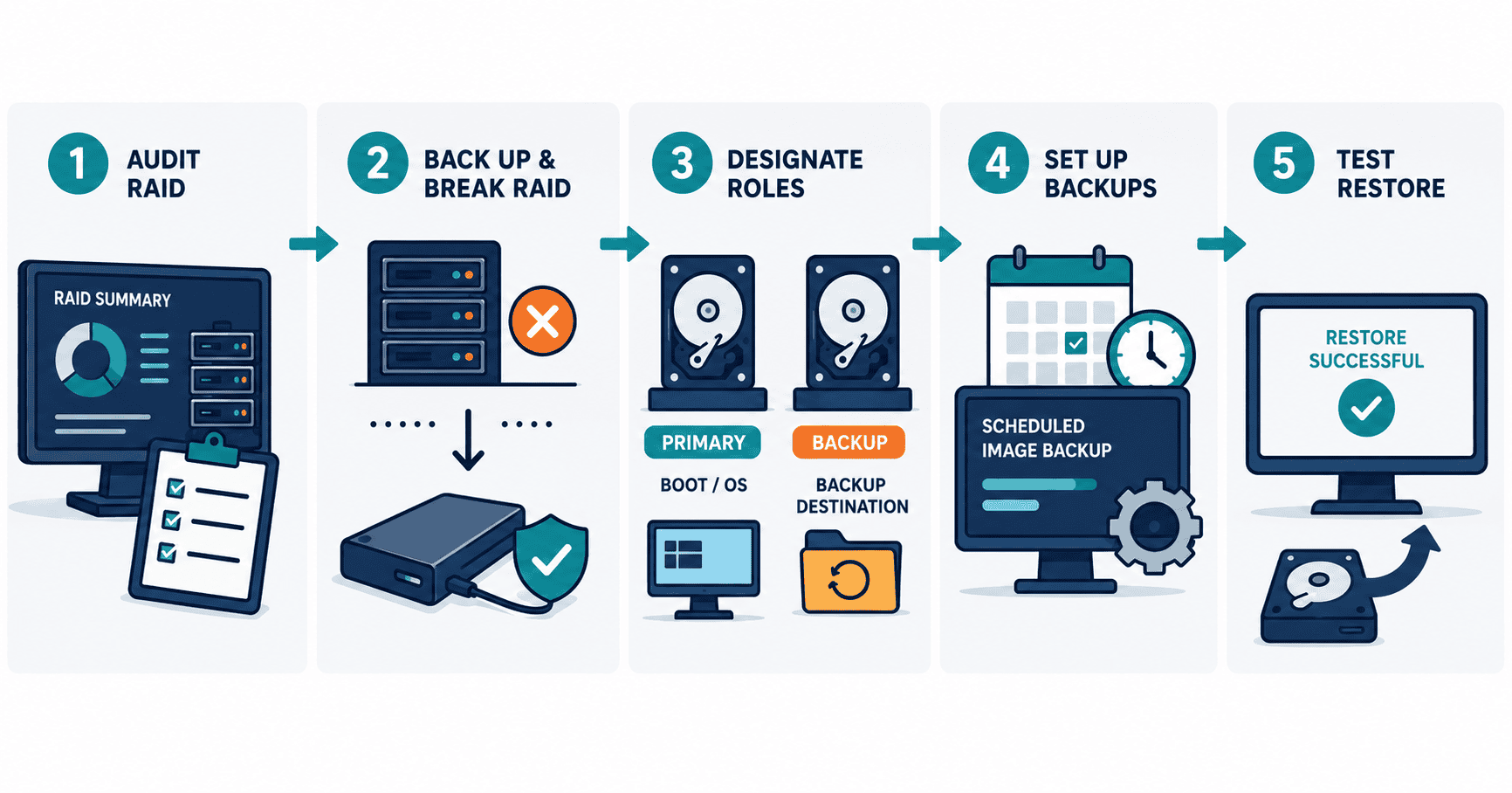
Step-by-Step: RAID to Backup Conversion
Step 1: Audit your current RAID configuration. Identify the RAID level, drive count, and controller type. Document the total capacity and how much is actively used. Check your RAID system's compatibility with imaging software before making changes.
Step 2: Back up critical data to an external location before proceeding THEN break the RAID array. Remove the mirror or parity relationship through your RAID controller’s BIOS or management utility. You’ll end up with independent drives. This step requires careful planning because it’s irreversible once confirmed.
Step 3: Designate primary and backup roles. Configure one drive as your boot and operating system disk. The second drive becomes your dedicated backup destination. In OEM machines, the “primary” should be the drive that best matches performance and endurance requirements (often the newer SSD), while the backup drive is sized for retention and restore speed.
Step 4: Set up automated image-based backups. Install Macrium Reflect and configure scheduled full and incremental backups from the primary drive to the secondary. Incremental imaging captures only what changed since the last backup, which keeps storage usage reasonable and backup windows short. If supported in your environment, enable anti-ransomware protections such as Macrium Image Guardian (MIG), which helps prevent unauthorized changes to backup image files.
Step 5: Test your restore process. A backup you’ve never tested isn’t a backup. Perform at least one full bare-metal restore to verify your images work. Understanding disaster recovery and restore procedures before an emergency hits is what separates a plan from a wish.
Why This Approach Beats RAID for Ransomware and Downtime
When ransomware hits a RAID array, every mirrored drive is encrypted simultaneously. With an image-based backup on a separate drive, you restore from the last clean image and lose minutes of work instead of days. The backup drive isn’t operating as a live mirror of every file write, which reduces the chance that an immediate corruption event takes out every copy at once.
Improper shutdowns are equally well-handled. A corrupted file system on the primary drive doesn’t automatically propagate into prior backup images, because those images represent point-in-time snapshots taken when the system was healthy. You roll back to the last known-good state and continue operation.
Restore speed matters enormously in OEM deployments. Every hour a customer’s machine is down may delay patient throughput, halt inspection/measurement, interrupt lab processing, or idle a critical workflow. Image-based recovery can bring a system back in minutes rather than the hours it takes to rebuild from scratch. That speed difference is where the ROI pays for itself, often within the first incident.
Building a Complete Protection Stack (OEM Edition)
For most OEM deployments, the most reliable “stack” is not RAID plus other tools - it’s a deliberate move away from RAID as a default design choice and toward image-based recovery as the baseline. RAID can still have a place in certain high-availability architectures, but if your goal is fast, predictable field recovery, RAID introduces cost and complexity without solving the incidents that actually drive downtime.
What to Standardize Instead: A Backup-First OEM Architecture
1) Primary system drive (simple, serviceable). Use a single OS/application drive sized for performance and endurance. Keeping storage simple reduces failure modes and makes troubleshooting and replacement easier for field teams.
2) Dedicated local backup target. Add a second internal drive (or an approved removable module) used exclusively for backups. The key difference from RAID is that backups are point-in-time, not live mirrored writes.
3) Automated image-based backup policy. Schedule full plus incremental images so you always have multiple restore points. This protects against bad updates, configuration drift, file corruption, and ransomware - scenarios RAID cannot roll back.
4) Recovery media and a documented field restore runbook. Ship every machine with tested recovery media (USB or a dedicated recovery partition, depending on your platform controls) and a standardized, step-by-step restore procedure your field team can execute consistently. The goal is repeatable recovery under pressure: a technician should be able to boot recovery media, locate the latest known-good image, restore to replacement hardware, and return the unit to service without improvisation.
5) Monitoring, verification, and compliance reporting. Backups that fail silently create the same outcome as no backups at all - only discovered later, during a critical outage. Standardize automated verification (image validation), alerting for missed schedules, and periodic reporting that’s easy to review during QBRs and customer audits. In regulated environments, tie backup evidence to asset ID/serial number and retain logs long enough to satisfy policy requirements. For more information on ensuring your systems are recovery ready, visit Macrium’s recovery toolkit.
Recommended Backup Cadence for OEM Field Systems
The right schedule depends on how often systems change, how costly downtime is, and how much storage you can dedicate locally. The goal is predictable restore points with minimal operational overhead.
| Machine Profile | Suggested Full Image | Suggested Incremental | Retention (Local) | Best Fit |
|---|---|---|---|---|
| Low-change kiosk / HMI | Monthly | Daily | 2–3 full sets | Stable deployments; fast rollback after power loss or misconfig |
| Edge gateway / data acquisition | Weekly | Every 4–12 hours | 2–4 weeks of incrementals | More frequent config changes; higher exposure to network threats |
| Clinical / lab / inspection platform | Weekly (or post-change) | Daily (or per shift) | Policy-driven | High cost of downtime; controlled change windows |
Operationally, many OEMs succeed with a simple rule: run a new full image before AND after any planned update (OS patches, driver upgrades, application revisions) and keep enough incrementals to roll back at least one business week.
Implementation Details OEM Teams Should Not Skip
Make Restores Hardware-Agnostic (When Possible)
Field reality includes motherboard revisions, swapped SSD models, and “we had to use what was in stock” replacements. Your recovery process should assume hardware drift. Build a standard restore workflow that includes driver availability, storage controller coverage, and a tested path to restore to replacement drives without manual rebuild steps.
Protect the Backup Target from Casual Tampering
If the backup disk is always writable by the running OS and accessible to every process, it’s easier for ransomware (or well-meaning users) to damage backup content. At minimum, apply least-privilege access controls and keep backup storage logically separated from application data paths. Where your platform allows it, use removable backup media handled only during service windows.
Document the “2 a.m. Procedure,” Not the Ideal Procedure
A field runbook should be optimized for speed and repeatability: what to plug in, what to boot, which image to choose, and how to confirm success. Avoid steps that rely on tribal knowledge. If a technician needs to make judgment calls under pressure, you’ll get inconsistent outcomes and longer MTTR.
RAID Still Has a Place - But Not as Your Backup
RAID can make sense when uptime during a single-drive failure is a hard requirement and the platform includes the monitoring and service model to support it (controller health, predictive failure alerts, validated rebuild procedures, and documented escalation paths). Even then, RAID is additive - not substitutive.
If your machine needs both high availability and fast recovery, the more defensible design is: use RAID for uptime and keep image-based backups for recovery. If your priority is field recoverability and support cost control, a single primary drive plus a dedicated image backup target often delivers better outcomes with less complexity.
OEM Decision Checklist: Are You Actually Protected?
-
Can you restore the full system (OS + apps + configuration) without reinstalling anything?
-
Do you have multiple restore points from different times (not a live mirror)?
-
Is the restore process tested on replacement hardware, not just the original build?
-
Can a field technician complete recovery in under one hour with a written runbook?
-
Do you have an off-box/offsite copy for theft, fire, or total device loss scenarios?
-
Do you receive alerts if backups stop running or validation fails?
Bottom Line: Stop Calling RAID a Backup
RAID is designed to keep systems online during a drive failure. Backups are designed to recover from what actually causes most OEM downtime: corruption, bad updates, ransomware, accidental deletion, and unpredictable customer environments.
If your current field strategy is “we have RAID,” you’re paying for redundancy without buying recoverability. A backup-first design - primary drive + dedicated image-based backups + tested restore media - turns recovery into a repeatable service action instead of a multi-day escalation.
If you want to reduce truck rolls, protect SLAs, and make time-to-recovery a product advantage, move from RAID-as-protection to imaging-as-standard.
Still relying on RAID as your recovery strategy? Speak with a Macrium expert about building a faster, more dependable approach to system recovery for OEM and operational environments.
Author: Brooke Watson, Content Marketing Manager, Macrium
Last Reviewed: 19/05/2026

Previous Post
The Essential Guide to Device Deployment for Education
Next Post
Best Backup Software 2026: The Essential Buyer’s Guide
